How to Measure Compute: Implications for the Tax Base
As AI is becoming widely adopted, there are increasing calls for reshaping our tax base, including from the developers of frontier models such as OpenAI and Anthropic.[1],[2] The concern is straightforward: if AI displaces human labor at scale, the labor-based taxes that governments depend on will need rethinking. Further complicating the matter is that deploying AI is currently tax-advantaged over hiring a human. A tax on ‘compute’ has emerged as one response to these issues and in this short note I focus on one very specific problem: if we were to tax ‘compute’, how would we measure it?
I’ll start off with a few of the first ideas that came to my mind and outline why I think they may not be the answer. I’ll then outline an alternative idea that I think could offer a better path forward. This is a difficult topic, and there are no perfect answers. My hope is that this note will spur discussion and creative ideas that help us work together to solve this perplexing issue.
AI, like many technologies, has strengths and limitations. AI is allowing for breakthroughs in healthcare, personalized learning at scale, and many other things that improve society. At the same time, serious concerns include environmental issues, loss of critical thinking, loss of jobs, a wealth oligopoly where only a few firms capture technology gains, and runaway electricity costs.
Each of these concerns could justify a compute tax in its own right, but all of them depend on the same foundational question: how do we measure compute well enough to tax it in line with the fundamentals of good tax policy? I’ll start off by discussing an idea tied closely to what currently dominates the AI discussion: LLMs.
Taxes that Seem Intuitive, but May Not Work Well
Idea 1: A Tax on Tokens:
This idea is intuitive. As the Tax Foundation notes, the key attributes of sound tax policy are simplicity, neutrality, transparency, and stability. Tokens can be transparently measured, are simple to think about, and at first glance appear to be a stable unit of LLM processing. But there are a few limitations with this type of tax:
Tokens vary based on the model. For example, the phrase “I’m wishing you a fantastic day. Appreciate you reading this!” is 12 tokens in GPT-5, and 15 tokens in GPT-3 when using OpenAI’s Tokenizer.
GPT-5.X & O1/3 Tokenization:
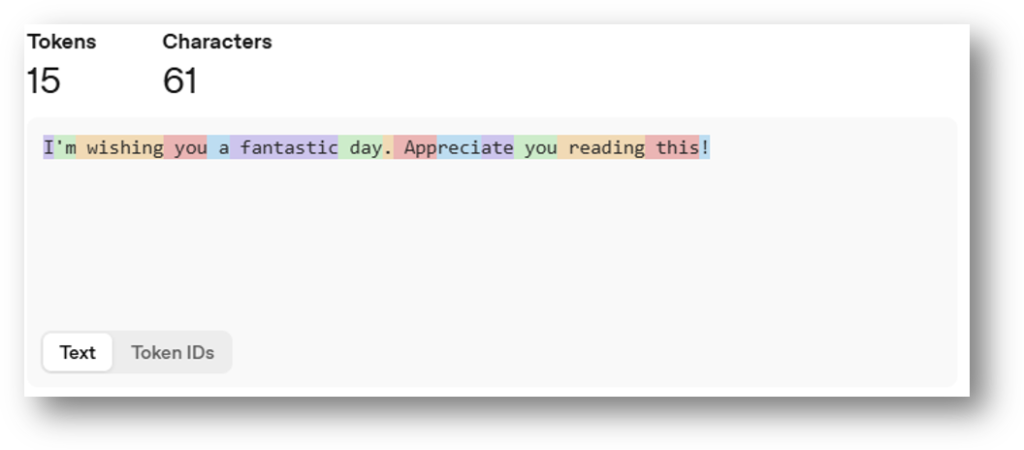
GPT-3 Tokenization:
Token usage could vary even more dramatically across the plethora of LLM choices that exist. In terms of avoidance behavior, the last thing we want is companies to use, or develop models that tokenize words in certain ways that are less efficient or effective but simply result in fewer taxes!
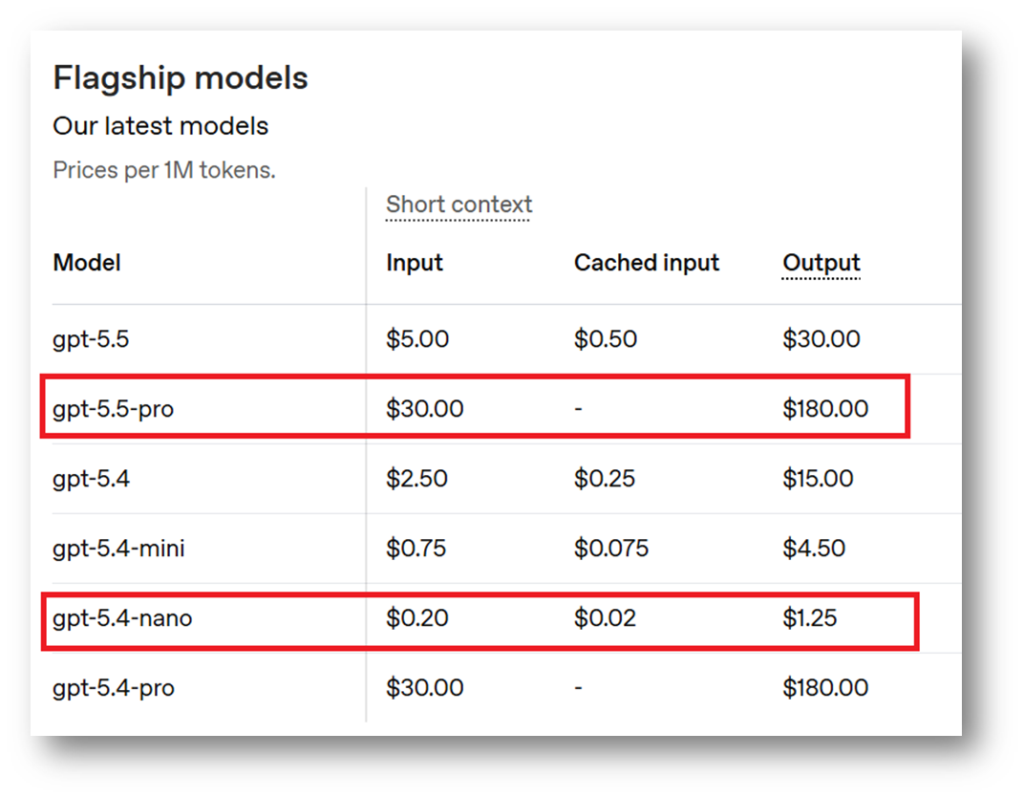
Additionally, tokens do not necessarily tie into the level of economic resources used or created. If we take market prices as at least somewhat reflective of economic reality, we can see that on a per token basis, OpenAI prices GPT-5.5-Pro input tokens at about 150x the cost of GPT-5.4.Nano input tokens. So even if all models broke input into the same number of tokens, a tax on tokens wouldn’t necessarily reflect the economic resources used or created in processing them or in outputting new tokens.
Finally, although LLMs are remarkable, there is more to AI than LLMs. Some of the most promising advancements in AI have come from combinations of LLMs with other models.[3] Additionally, several leading voices in AI are spearheading labs to go beyond LLMs.[4] Other forms of AI exist including machine learning, computer vision, and advancements in physical-based AI like robots and self-driving cars. None of these other forms of AI would be affected by a tax on tokens.
Idea 2: Tax on Processing Power
This idea also has merit and certainly addresses some of the issues with a tax on tokens in terms of more broadly covering different aspects of AI outside of LLMs, and also in addressing the issue around one token not necessarily having the same economic value as another. “Compute” can be directly traced to the processing power of the underlying CPUs/GPUs/TPUs, and these directly influence the power of the AI it is driving. That said, there are at least two concerns with how this would work.
First, how is compute measured? A measure like GHz is simply how fast the unit does one processing cycle, but what that means for actual output will vary dramatically by architecture. For example, I created this graph below using scores from cpubenchmark.net to compare a 3.8GHz CPU (Pentium 4, 2005 release) to a 2.2 GHz CPU (Intel Core Ultra 7, 2024 release), prompting ChatGPT 5.5 with that data and instructions to create the graphic.
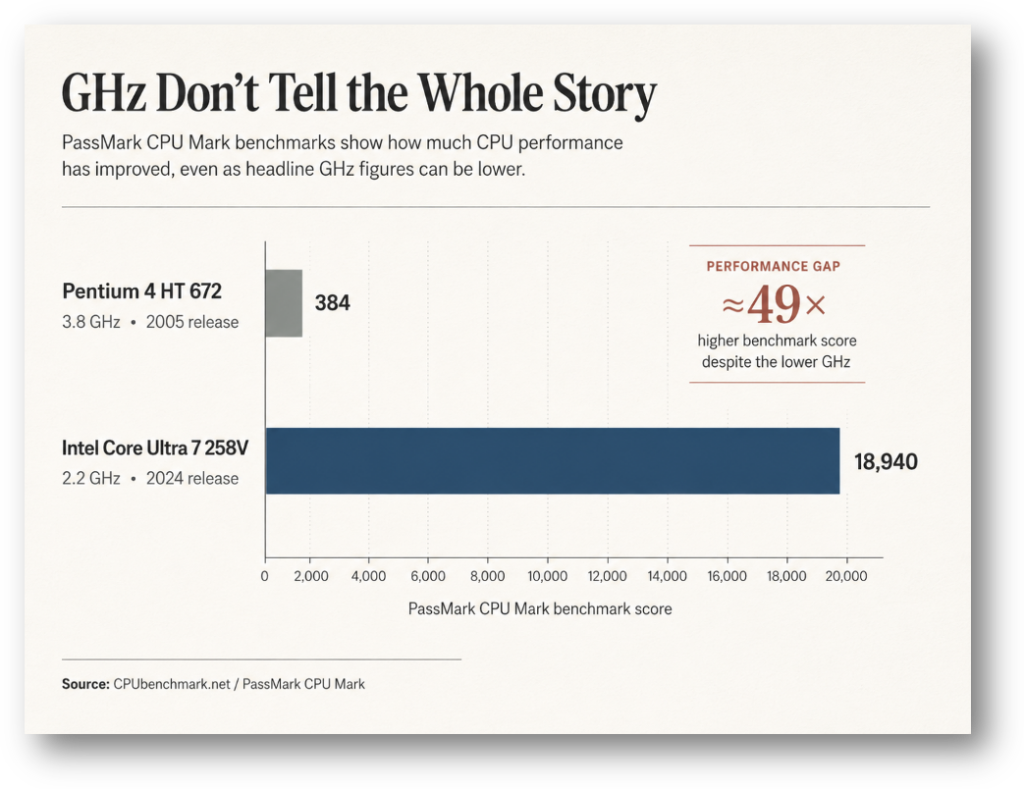
Although this illustration relies on CPUs, compute could be driven by GPUs or by Google’s relatively new TPUs. Other processing units like a GPU would require an entirely different benchmark, which is another strike against a tax on compute, as the tax system is not traditionally known for its nimbleness in adopting quickly to new technologies (like changes in what drives compute).
To address issues with measuring processing power or comparisons across different types of processing units, one thing that came to mind was a sales tax on compute components. A sales tax would be related to the sale price of the product, and it is reasonable to expect higher powered components to cost more. However, such a tax could disincentivize American investment in technology. Further, whether the tax was on processing power directly, or a sales tax on the sales price of these components, a real challenge with any tax on compute is potential erosion of the tax base through compute simply being setup overseas.[5]
An Alternative Idea: A Tax on Electricity Use by AI-Focused Data Centers
It is always easier to be a critic than to propose a solution, so let me put forth a kernel of an idea as an alternative to the taxes outlined above: a direct tax on electricity used by the data centers that power AI.
Electricity use for compute can in many ways be thought of as similar togas for gasoline powered cars. Compute power needs electricity to work, more efficient products use less, and more powerful products will generally use more. Electricity powers many types of compute, from LLMs to traditional AI. Further, like refineries and gas pumps, both electricity use and data centers are relatively easy to identify and measure.
People are very concerned about the growth of data centers, along with their electricity use. A tax on electricity use by data centers, with at least some portion earmarked for reinvestment in the local community, is worth considering.[6] While the overall portion of AI-related energy use is currently relatively small, this report from the International Energy Agency projects it will grow very quickly.
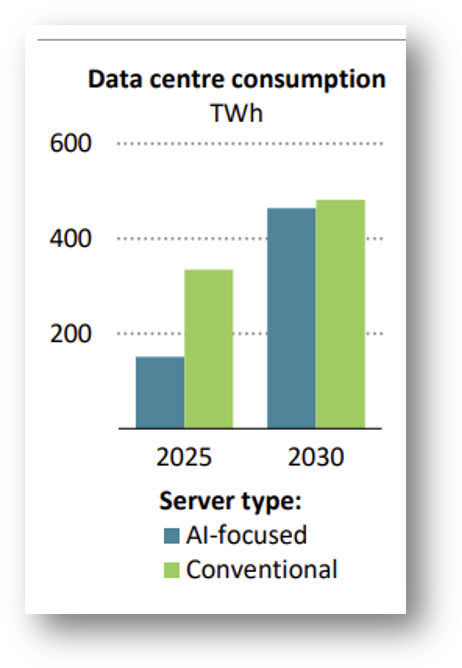
A key benefit of a tax on electricity use by AI-focused data centers is that it generalizes to whatever processing unit the data center is using, rewards efficiency, and directly addresses growing concerns around the environmental dimension of AI use. It also directly addresses important concerns about AI energy use.
To the extent a data center provider chooses to use their own power source, it is worth considering if this should be taxed too, albeit perhaps at a diminished rate as it alleviates concerns about excessive demand on the energy grid.
Measured against the Tax Foundation’s four principles, the electricity approach holds up reasonably well. Electricity use is universally metered and the definition of a data center is administrable, making compliance relatively simple and transparent. It is broadly neutral across processing architectures, as AI use draws power regardless of its form. Further, unlike token definitions or hardware benchmarks that evolve rapidly, electricity is a stable base that doesn’t require the tax code to keep pace with model architecture changes.
One weakness worth acknowledging is that with the tax being on data centers, some electricity that is used to power AI would not be captured, especially for AI use that occurs at the local computer level (LM Studio type tools, built-in AI, etc.), or even general business use of on-premises servers that don’t rely on large external data centers. However, I think this weakness is less severe than the weaknesses found in either a tax on tokens or a tax on compute.
In Conclusion: No Easy Answers
As we think about taxes in the age of AI, there are no easy answers, and I do not think I have the perfect solution. But if you made it this far I hope you found at least a tiny bit of helpfulness in the essay, and as illustrated in the tokenizer example above, I’m wishing you a fantastic day. Appreciate you reading this!
***
Author note: I relied on several AI models in thinking through, researching, writing, and revising this draft, including Gemini, ChatGPT, and Claude.
[1] “Industrial Policy for the Intelligence Age: Ideas to Keep People First”. OpenAI April 6, 2026. Available at: https://openai.com/index/industrial-policy-for-the-intelligence-age/
[2] See “Preparing for AI’s economic impact: exploring policy responses”, Anthropic October 14, 2025. Available at: https://www.anthropic.com/research/economic-policy-responses.
[3] https://www.science.org/doi/10.1126/science.ade9097. Credit to Cal Newport for frequently discussing this on his podcast.
[4] https://www.technologyreview.com/2026/04/21/1135650/world-models-ai-artificial-intelligence/
[5] Thanks to Jeff Hoopes for pointing this out.
[6] Two things can be true with electricity use with AI. First, an individual query uses about as much electricity as watching 8-10 seconds of Netflix (credit to Ethan Mollick). Second, training the models certainly takes far more power than using them, and while individual uses may be small, do they add up.
